在Azure VM上安装配置Hadoop大数据分析平台
一.创建配置Azure Virtual machines
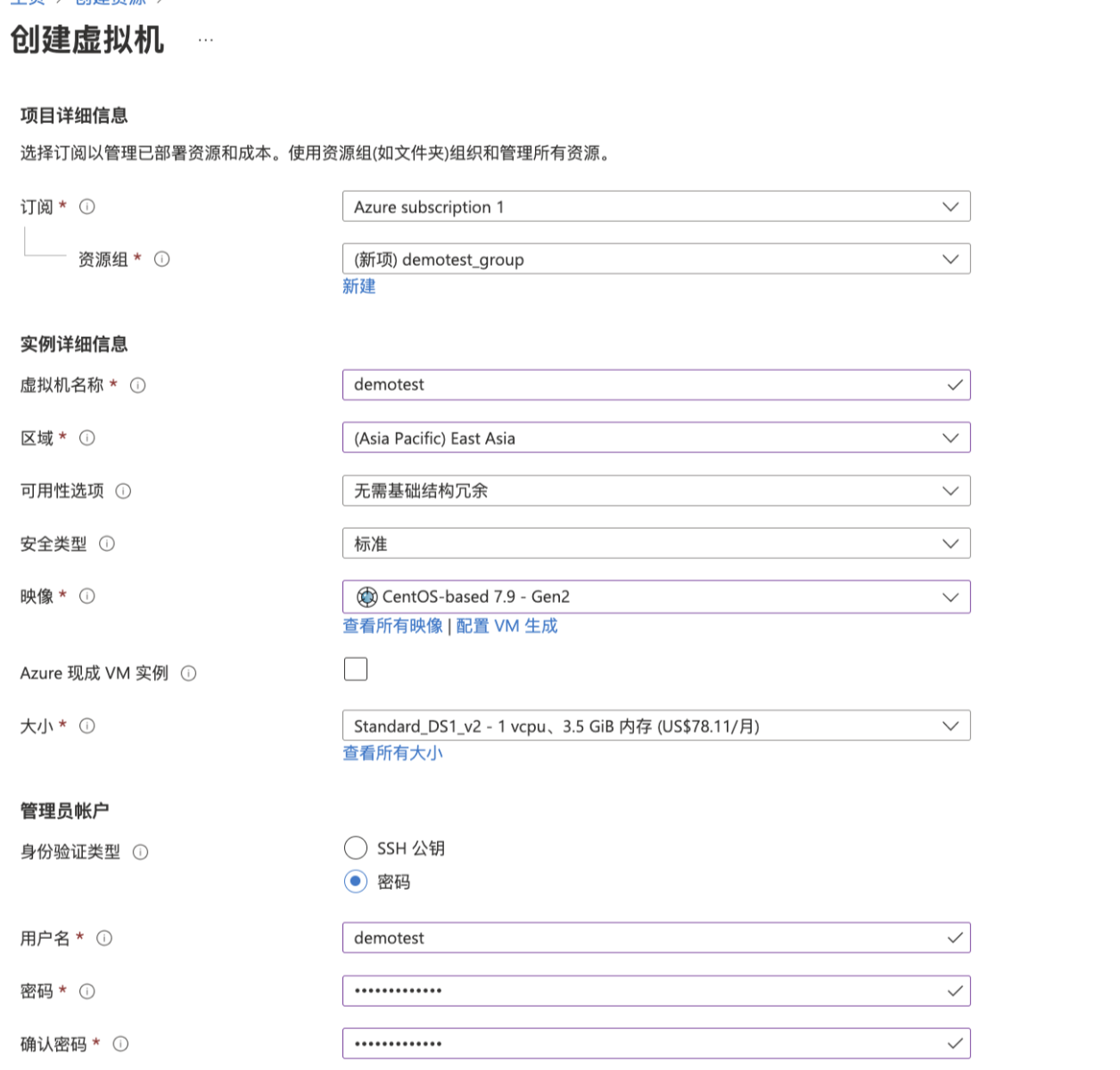
1.配置基本的Azure VM信息(包括订阅、资源组、实例详细信息,管理员账号及入站端口规则),具体配置如下所示:
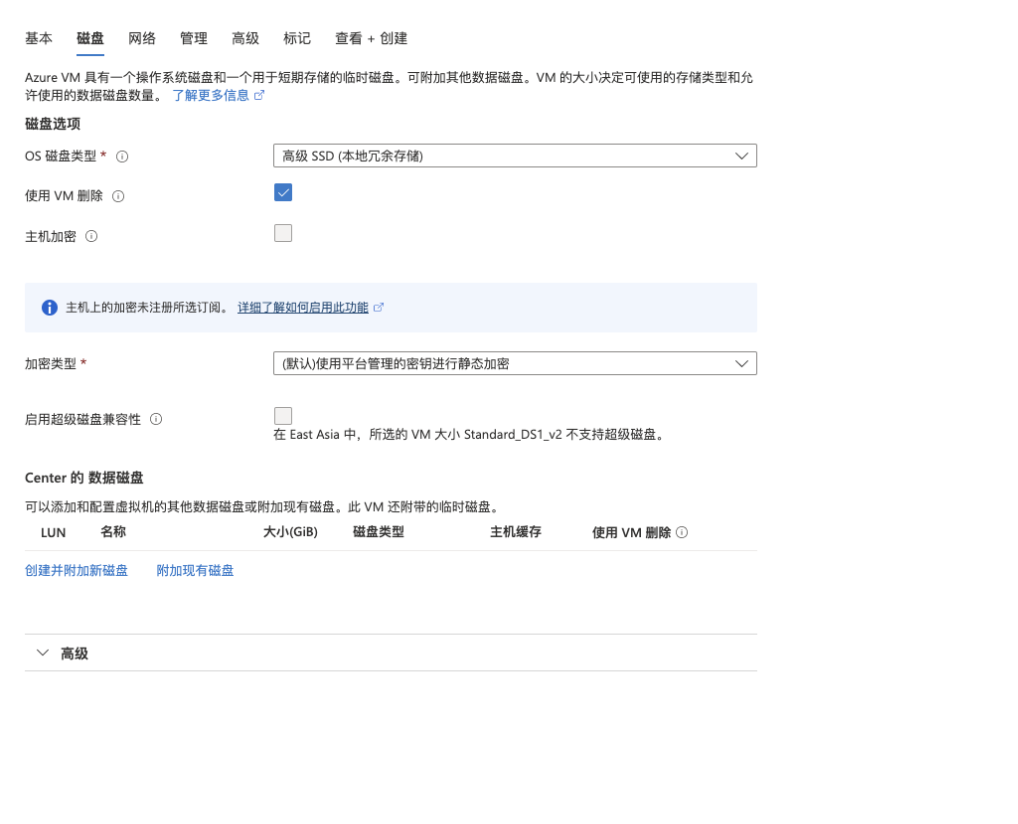
2.配置磁盘信息(配置相关磁盘类型及加密类型)具体配置如下所示:
3.配置网络接口信息(虚拟网络、子网、公网IP、公共出入站端口等)具体配置如下所示:
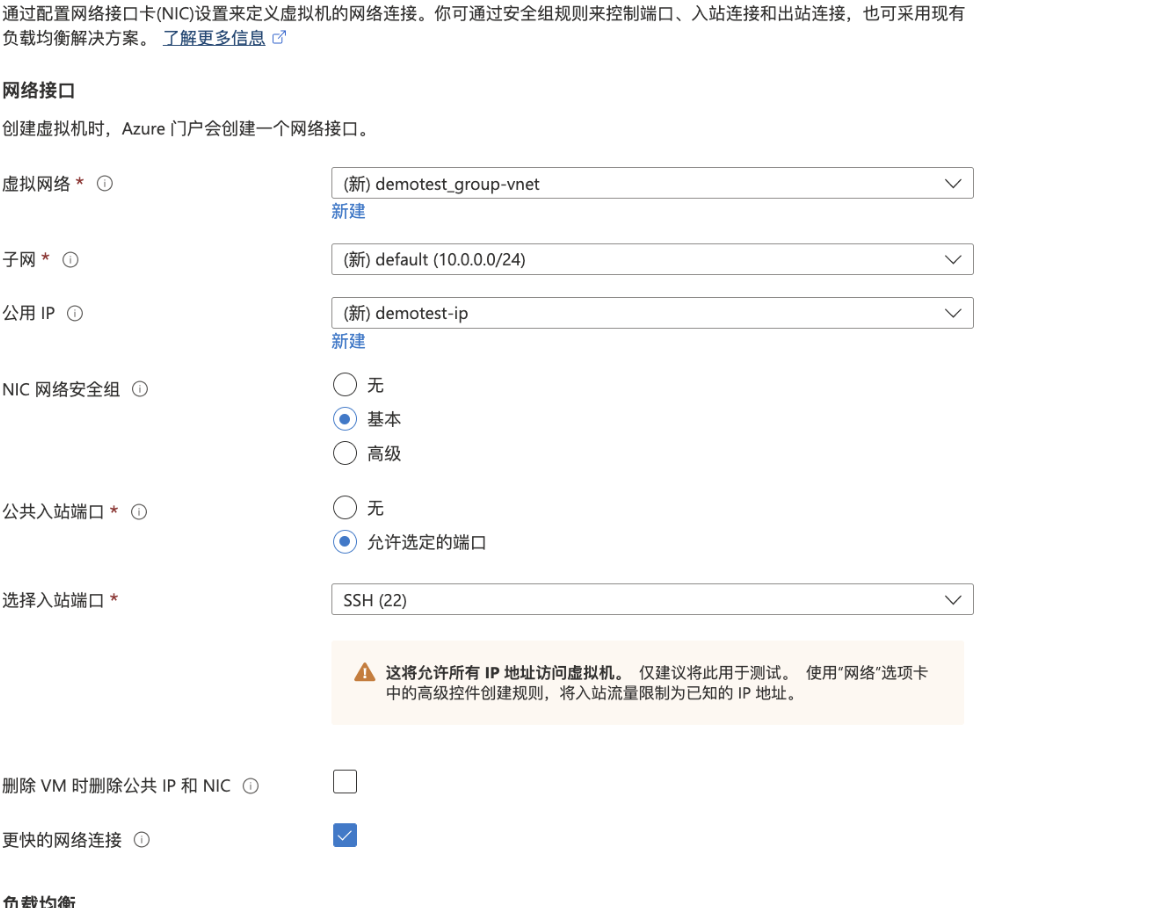
4.配置监视和管理
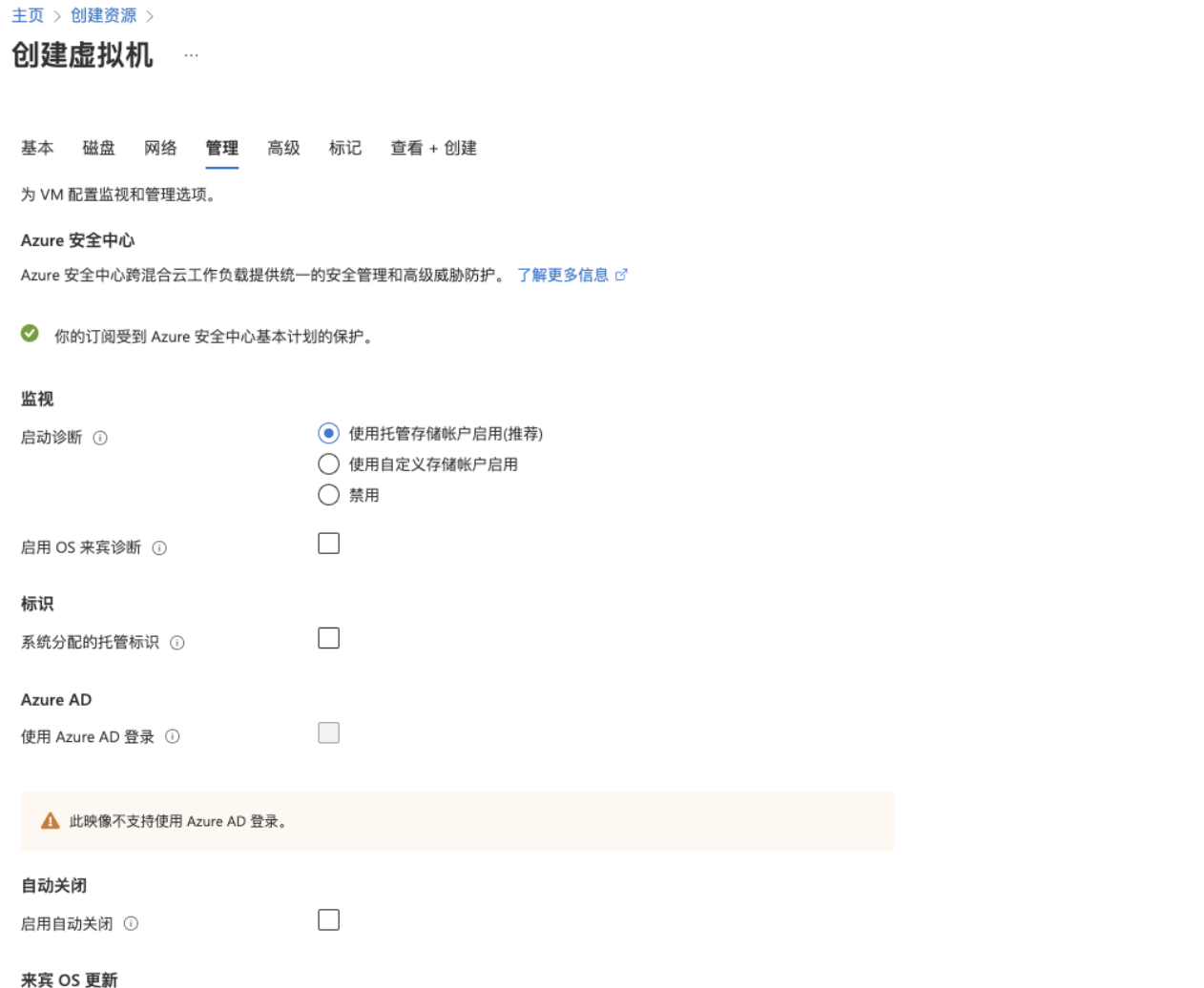
5.查看并创建虚拟机

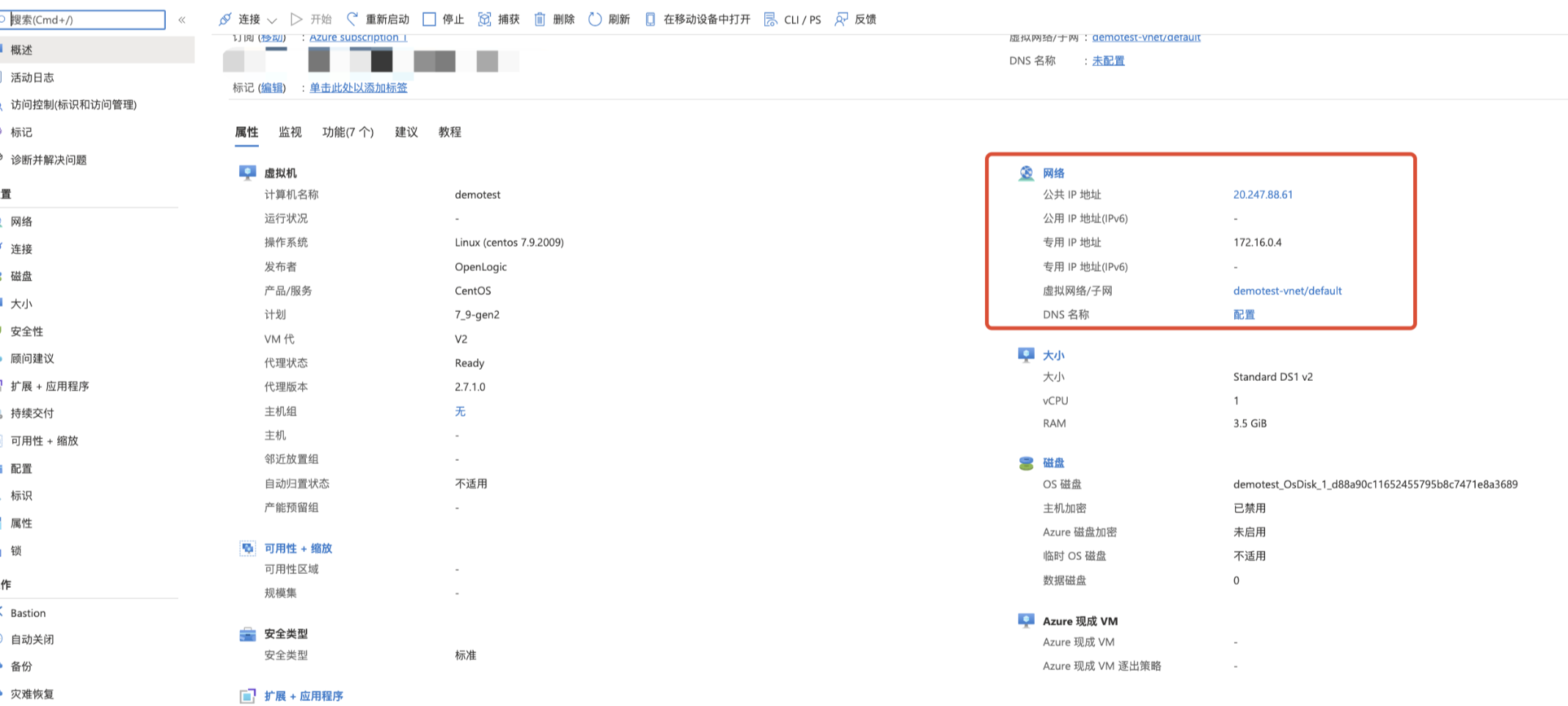
6.如下图所示可以看到虚拟机资源管理页面
二.下载JDK1.8
1.通过执行如下命令来下载JDK1.8
wget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz

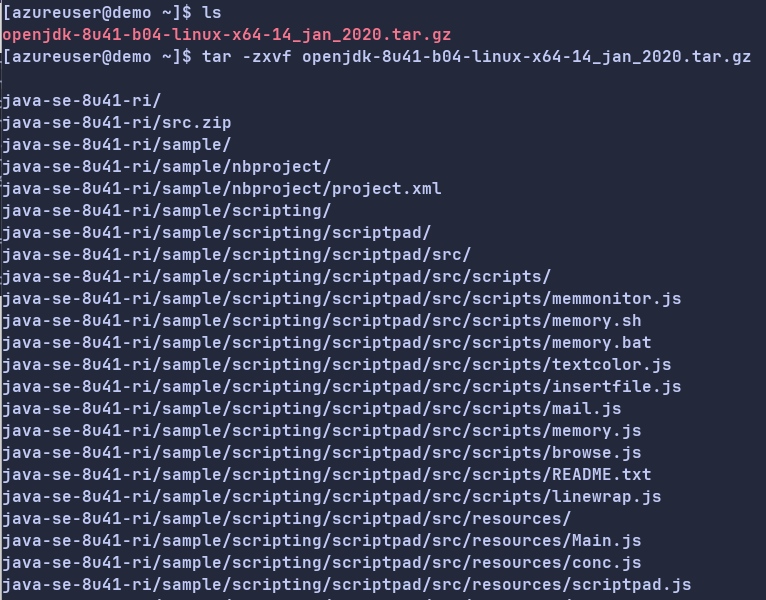
2.执行如下命令来解压下载的JDK 1.8安装包
tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz
3.执行如下命令来移动并重命名JDK安装包。
sudo mv java-se-8u41-ri/ /usr/java8

4.执行如下命令来配置Java环境变量。
sudo sh -c "echo 'export JAVA_HOME=/usr/java8' >> /etc/profile"
sudo sh -c 'echo "export PATH=\$PATH:\$JAVA_HOME/bin" >> /etc/profile'
source /etc/profile

5.执行以下命令,查看JDK是否成功安装。
java -version

三.安装Hadoop
1.执行以下命令,下载Hadoop安装包。
wget https://mirrors.bfsu.edu.cn/apache/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz

2.执行以下命令,将Hadoop安装包解压至/opt/hadoop。
sudo tar -zxvf hadoop-3.2.4.tar.gz -C /opt/
sudo mv /opt/hadoop-3.2.4 /opt/hadoop
3.执行以下命令,配置Hadoop环境变量。
sudo sh -c "echo 'export HADOOP_HOME=/opt/hadoop' >> /etc/profile"
sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/bin' >> /etc/profile"
sudo sh -c "echo 'export PATH=\$PATH:/opt/hadoop/sbin' >> /etc/profile"
source /etc/profile

4.执行以下命令,修改配置文件yarn-env.sh和hadoop-env.sh。
sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/yarn-env.sh'
sudo sh -c 'echo "export JAVA_HOME=/usr/java8" >> /opt/hadoop/etc/hadoop/hadoop-env.sh'

5.执行以下命令,测试Hadoop是否安装成功。
hadoop version

四.配置Hadoop
1.执行以下命令,进入编辑页面。
sudo vim /opt/hadoop/etc/hadoop/core-site.xml
输入i,进入编辑模式
2.在节点内,插入如下内容。
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>location to store temporary files</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>

按
Esc,退出编辑模式,并输入:wq保存并退出。
3.修改Hadoop配置文件hdfs-site.xml。
sudo vim /opt/hadoop/etc/hadoop/hdfs-site.xml
输入i,进入编辑模式。
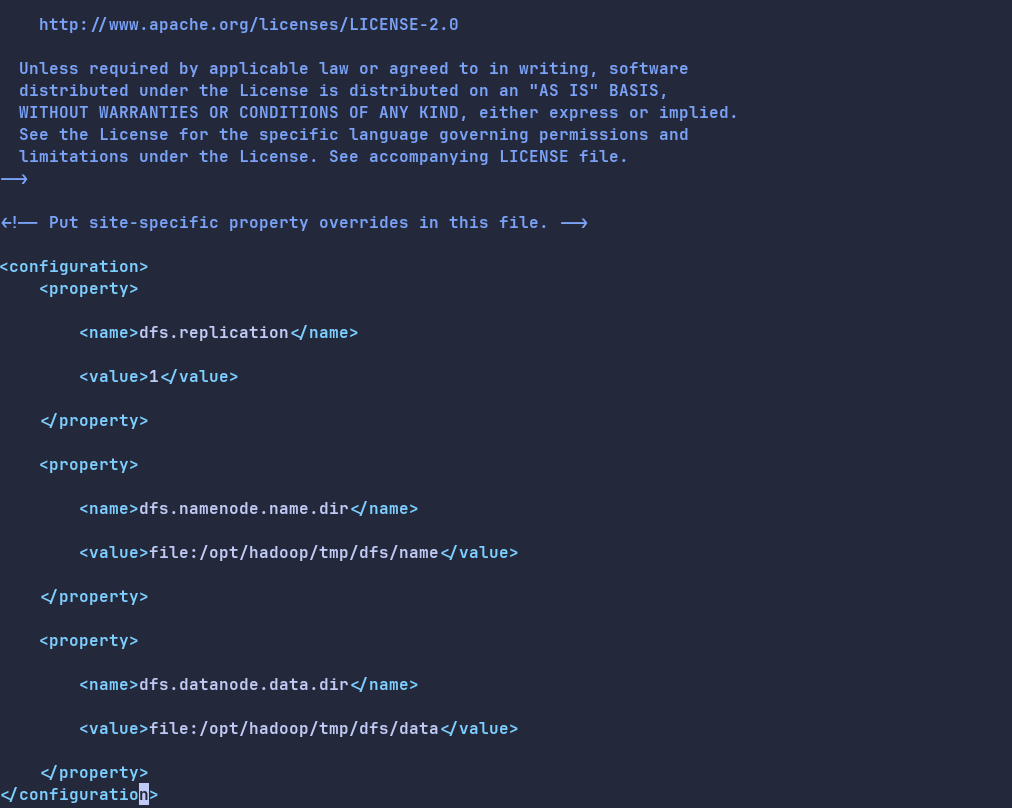
在<configuration></configuration>节点内,插入如下内容。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>
按
Esc,退出编辑模式,并输入:wq后保存并退出。
五.配置SSH免密登录
1.执行以下命令,创建公钥和私钥。
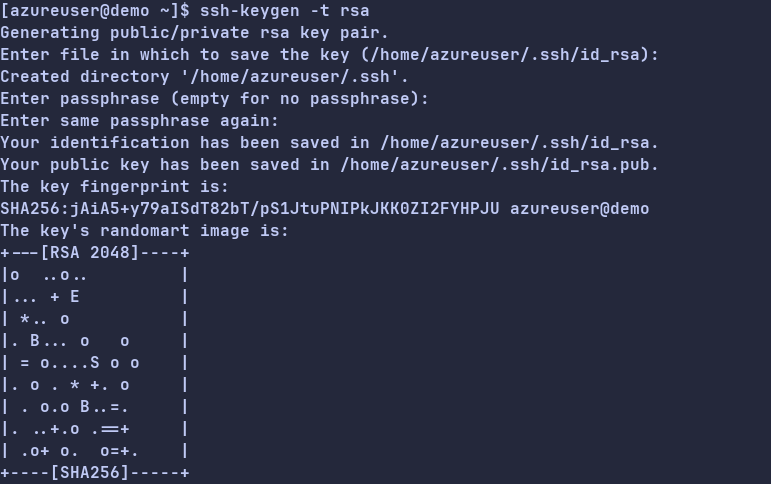
ssh-keygen -t rsa
回显信息如下所示,表示创建公钥和私钥成功。
2.执行以下命令,将公钥添加到authorized_keys文件中。
cd .ssh
cat id_rsa.pub >> authorized_keys

六.启动Hadoop
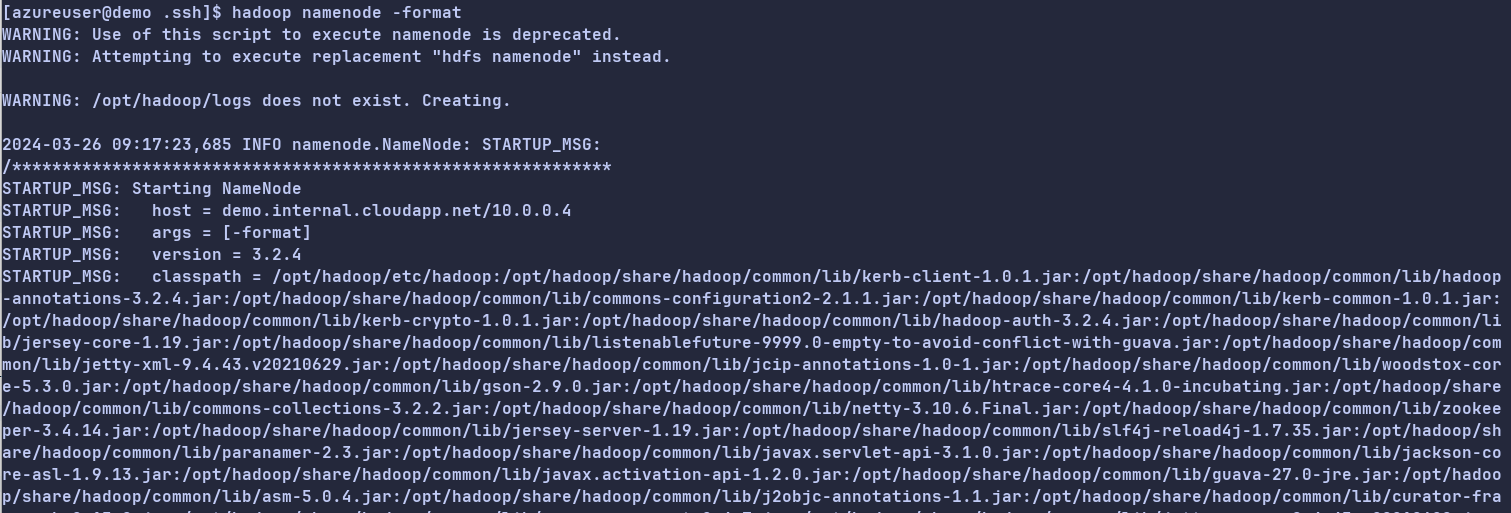
1.执行以下命令,初始化namenode<span> </span>。
hadoop namenode -format
2.启动Hadoop。
执行以下命令,启动HDFS服务。
start-dfs.sh
回显信息如下所示时,表示HDFS服务已启动。
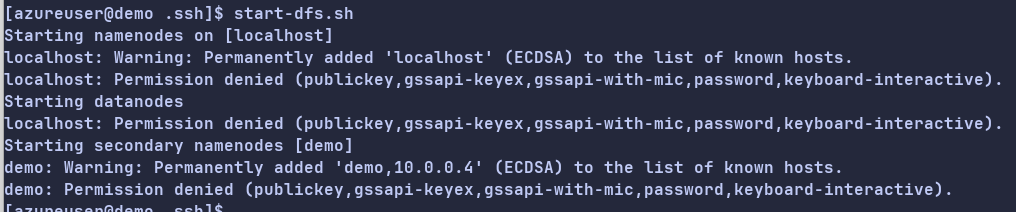
执行以下命令,启动YARN服务。
这个脚本会启动ResourceManager、NodeManager和ApplicationHistoryServer等组件,从而启动YARN服务。
start-yarn.sh
3.执行以下命令,可以查看成功启动的进程。
jps

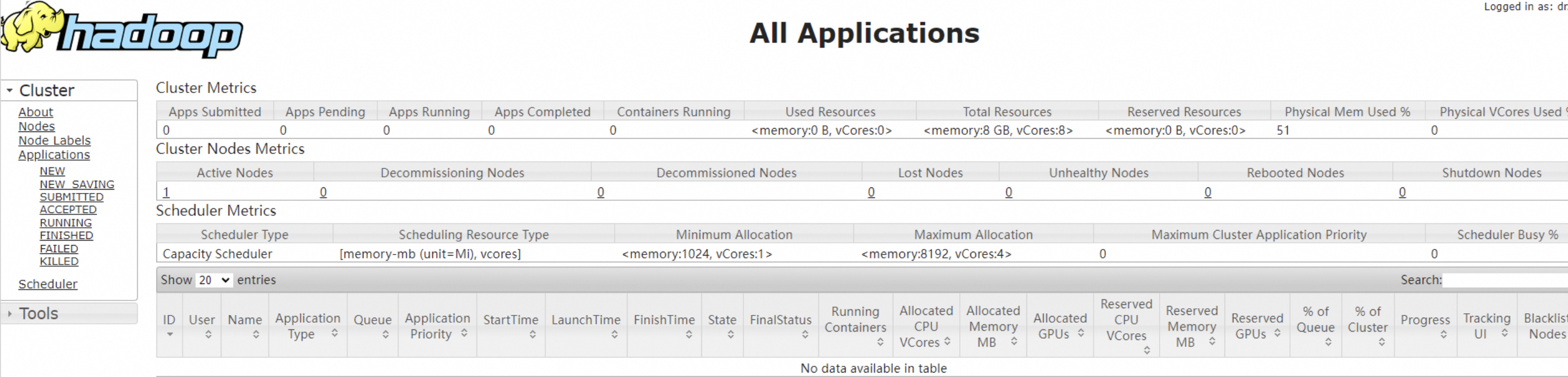
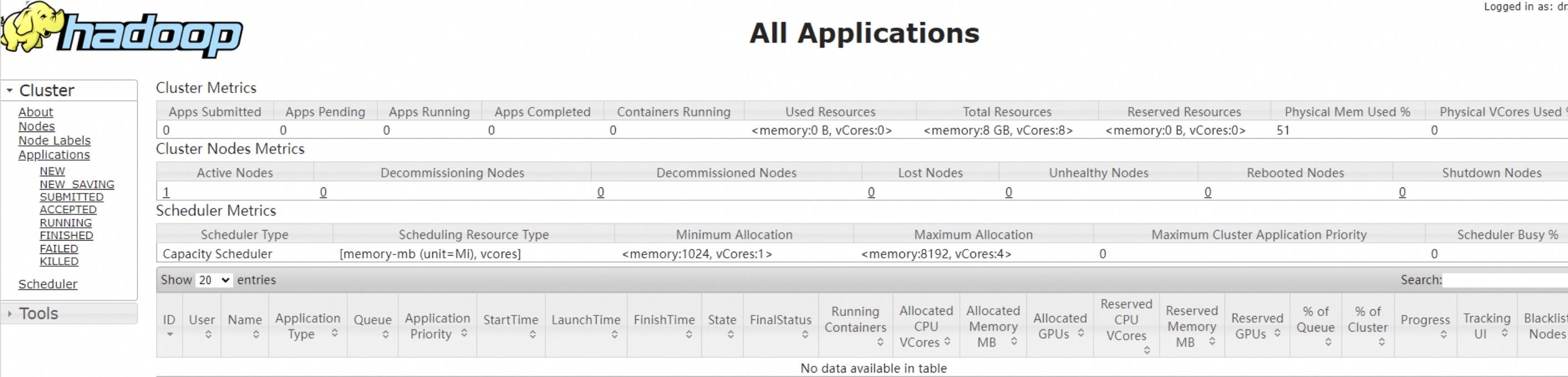
4.在本地浏览器地址栏输入http://<AzureVM公网IP地址>:8088,可访问YARN的Web UI界面,如下图所示,我们已经在Azure VM上成功搭建了Hadoop分布式环境。
.png)